🎉 Welcome to the 4th part of Delta Lake essential fundamentals: the practical scenarios! 🎉
There are many great features that you can leverage in delta lake, from the ACID transaction, Schema Enforcement, Time Traveling, Exactly One semantic, and more.
Let’s discuss two common data pipelines patterns and solutions:
Spark Structured Streaming ETL with DeltaLake that serves multiple Users
Spark Structured Streaming-
Apache Spark structured steaming are essentially unbounded tables of information. There is a continuous stream of data ingested into the system. As developers, we write the code to process the data continuously.
ETL stands for Extract, Transform and Load.
Let’s understand what are Delta Lake compact and checkpoint and why they are important.
Checkpoint
There are two known checkpoints mechanism in Apache Spark that can confuse us with DeltaLake checkpoint, so let’s understand them and how they differ from each other:
Spark RDD Checkpoint
Checkpoint in Spark RDD is a mechanism to persist current RDD to a file in a dedicated checkpoint directory while all references to its parent RDDs are removed.
This operation, by default, breaks data lineage when used without auditing.
In the previous part, you learned what ACID transactions are. In this part, you will understand how Delta Transaction Log, named DeltaLog, is achieving ACID.
Transaction Log
A transaction log is a history of actions executed by a (TaDa 💡) database management system with the goal to guarantee ACID properties over a crash.
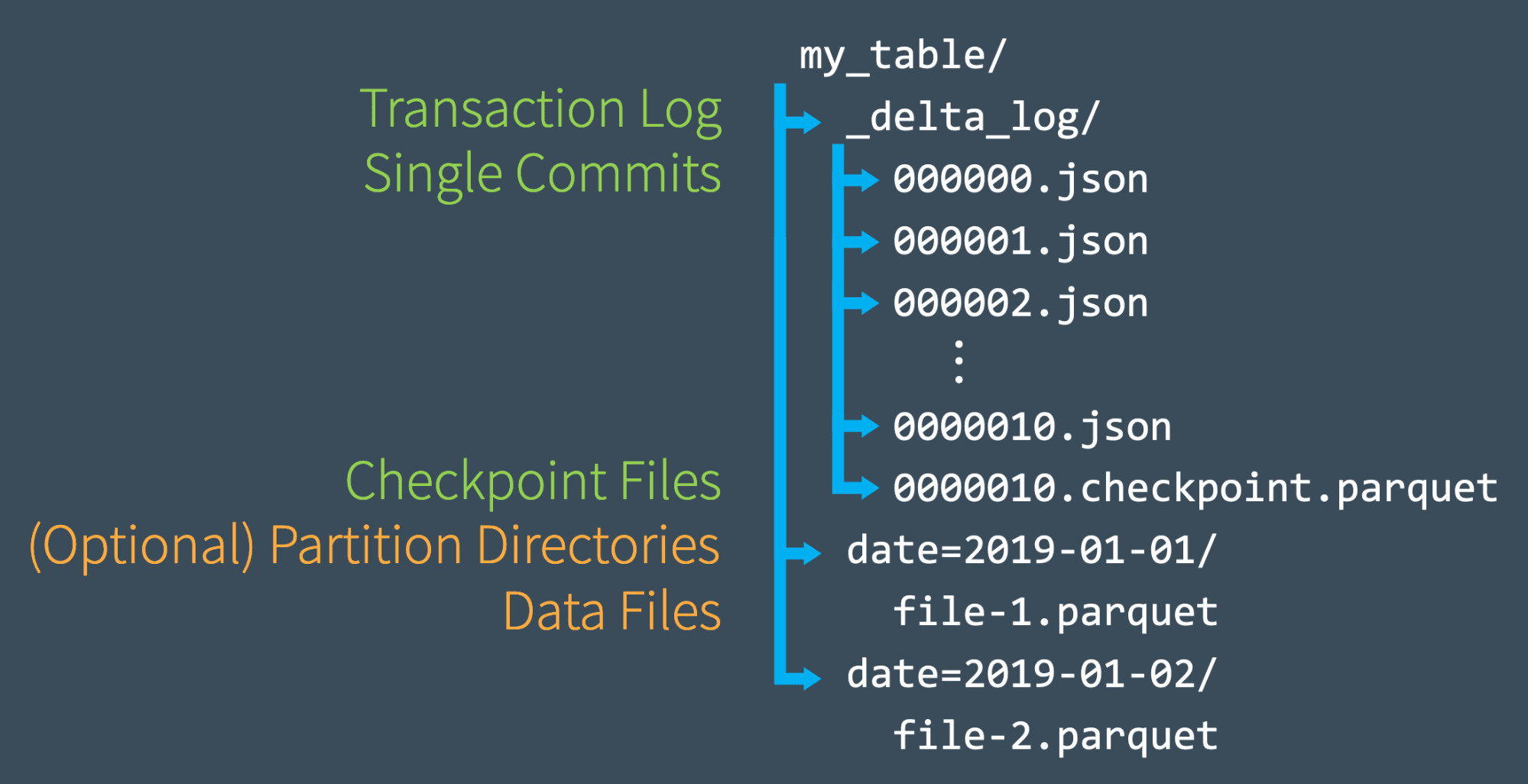
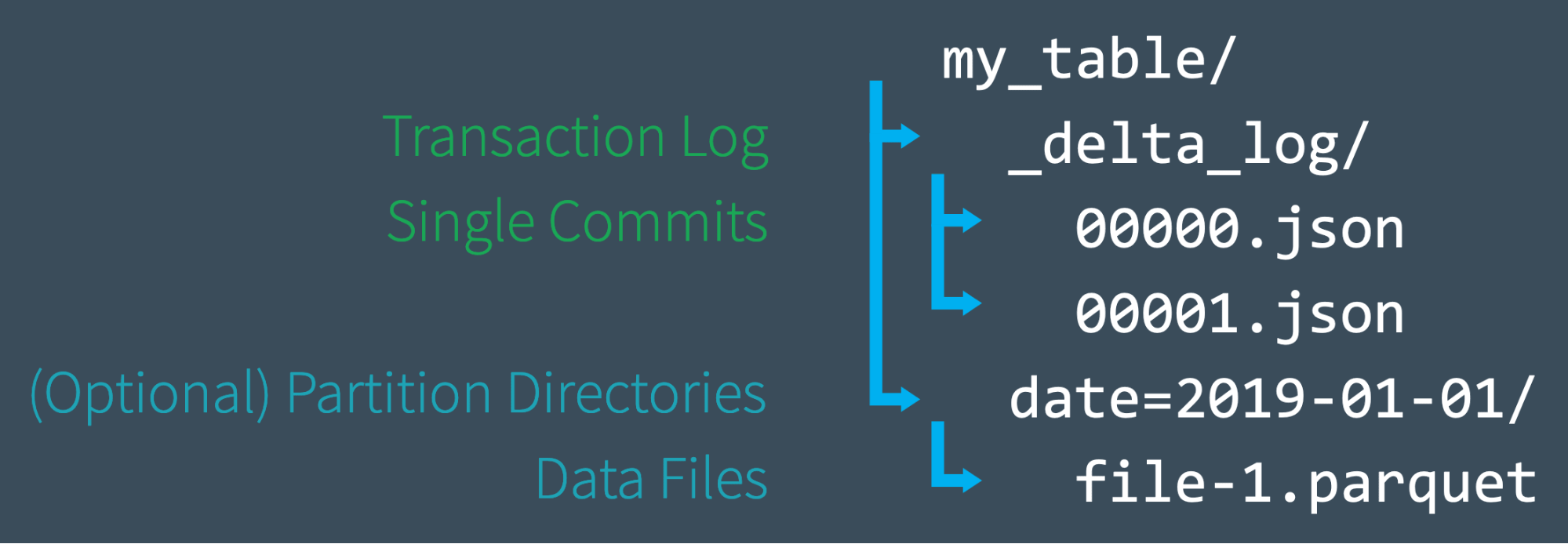
DeltaLake transaction log - DetlaLog
DeltaLog is a transaction log directory that holds an ordered record of every transaction committed on a Delta Lake table since it was created.
The goal of DeltaLog is to be the single source of truth for readers who read from the same table at the same time. That means, parallel readers read the exact same data.
This is achieved by tracking all the changes that users do: read, delete, update, etc. in the DeltaLog.
delta-rs - Rust library for binding with Python and Ruby.
connectors - Connectors to popular big data engines outside Spark, written mostly in Scala.
Delta provides us the ability to “travel back in time” into previous versions of our data, scalable metadata - that means if we have a large set of raw data stored in a data lake, having metadata provides us with the flexibility needed for analytics and exploration of the data. It also provides a mechanism to unify streaming and batch data. Schema enforcement - handle schema variations to prevent insertion of bad/non-compliant records, and ACID transactions to ensure that the users/readers never see inconsistent data.